
![]()
目次
記事の内容
GoogleスプレッドシートをAPIからpythonを使用して操作するまで
この記事の内奥は2020/06/06時点のクイックスタートの内容を参考にしています。
Google Sheets APIv4 クイックスタート
Step1 Google Sheets APIの有効化
「Enable the Google Sheets API」ボタンを押下し、自分のchilentを選択します。
今回は「Desktop app」にした。
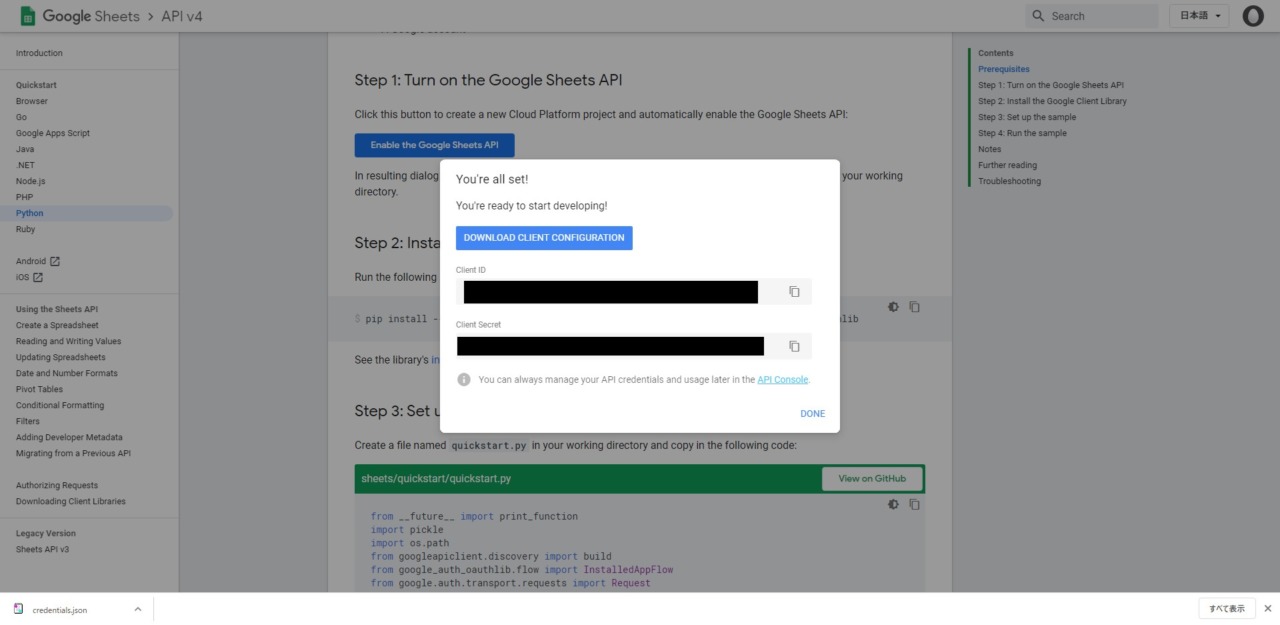
「CREATE」を押下すると以下の画像のようにClientIDとシークレットが発行される。
「DOWNLOAD CLIENT CONFIGURATION」を押下することでcredentialのjsonが保存される。
Step2 Google Client Library のインストール
pipでインストール可能。
pip install --upgrade google-api-python-client google-auth-httplib2 google-auth-oauthlib
インストールオプションについてはこちらから
Step3 サンプルの実行の設定
sheet / quickstart / quickstart.pyという作業ディレクトリを作成し
sampleをコピーする
quickstart.py
from __future__ import print_function
import pickle
import os.path
from googleapiclient.discovery import build
from google_auth_oauthlib.flow import InstalledAppFlow
from google.auth.transport.requests import Request
# If modifying these scopes, delete the file token.pickle.
SCOPES = ['https://www.googleapis.com/auth/spreadsheets.readonly']
# The ID and range of a sample spreadsheet.
SAMPLE_SPREADSHEET_ID = '1BxiMVs0XRA5nFMdKvBdBZjgmUUqptlbs74OgvE2upms'
SAMPLE_RANGE_NAME = 'Class Data!A2:E'
def main():
"""Shows basic usage of the Sheets API.
Prints values from a sample spreadsheet.
"""
creds = None
# The file token.pickle stores the user's access and refresh tokens, and is
# created automatically when the authorization flow completes for the first
# time.
if os.path.exists('token.pickle'):
with open('token.pickle', 'rb') as token:
creds = pickle.load(token)
# If there are no (valid) credentials available, let the user log in.
if not creds or not creds.valid:
if creds and creds.expired and creds.refresh_token:
creds.refresh(Request())
else:
flow = InstalledAppFlow.from_client_secrets_file(
'credentials.json', SCOPES)
creds = flow.run_local_server(port=0)
# Save the credentials for the next run
with open('token.pickle', 'wb') as token:
pickle.dump(creds, token)
service = build('sheets', 'v4', credentials=creds)
# Call the Sheets API
sheet = service.spreadsheets()
result = sheet.values().get(spreadsheetId=SAMPLE_SPREADSHEET_ID,
range=SAMPLE_RANGE_NAME).execute()
values = result.get('values', [])
if not values:
print('No data found.')
else:
print('Name, Major:')
for row in values:
# Print columns A and E, which correspond to indices 0 and 4.
print('%s, %s' % (row[0], row[4]))
if __name__ == '__main__':
main()Step4 サンプルの実行
python quickstart.pyをコマンドを使用して実行する
動作は以下のようになる。
- デフォルトブラウザで新しいウィンドウかタブで開けばOK.
失敗した場合は、コンソールからURLをコピーして手動でブラウザを開く。 - Acceptボタンを押下する
- サンプルは自動で続行され、ウィンドウかタブが閉じる。
※ 承認情報はファイルに保存されるため、その後の実行では承認は求められない。
おまけ スプレッドシートから値の取得
sheet.values().get()
スプレッドシートから値を取得するにはsheet.values().get()を使用する。
リファレンス:spreadsheets.values.get
引数
-
spreadsheetId
string スプレッドシートのID
スプレッドシートのIDはスプレッドシート開いた時のURL。以下のようになっている。
https://docs.google.com/spreadsheets/d/spreadsheetId/edit#gid=sheetId -
range
string 取得する範囲
範囲の選択方法は「A1表記」と言われるもの。
例
・Sheet1!A1:B2 Sheet1の1列、2行目までの2つのセルを参照する
・Sheet1!A:A Sheet1の1列目全行のセルを参照する
・Sheet1!1:2 Sheet1の2行目全列のセルを参照する
・Sheet1!A5:A Sheet1の1列目の5行目以降の全てのセルを参照する
・A1:B2 最初に表示されるシートの1列目かつ2行目までの2セルを参照する
・Sheet1 Sheet1の全てのセルを参照する
例
sheet = service.spreadsheets() # serviceはサンプルにもある、authの結果
res = sheet.values().get(spreadsheetId="1oxxxxxxxxxxxxxxxxxxxxxlHuRwKE",range="Data!A3:C600").execute()
戻り値
dict型で以下の構成。
取得した結果は「values」に格納される。
jsonするなり、そのままループを回すなり可能。
{
"range": string,
"majorDimension": enum (Dimension),
"values": [
array
]
}おまけ 行の削除
sheet.batchUpdate()
行の削除にはbatchUpdate()を使用する。
リファレンス:spreadsheets.batchUpdate メソッド
引数
-
spreadsheetId
string スプレッドシートID -
body
RequestBody
{
requests{
"deleteDimension": {
"range": {
"sheetId": sheet_id, // スプレッドシートIDとは別のため注意。
"dimension": "ROWS",
"startIndex": sp_row, // 行の初め(指定行を含む)
"endIndex": sp_row + 1 // 行の終わり(指定行は含まない)
}
}
}
}
例
sheet_range = self.config.get("google_sp","range")
sheet = service.spreadsheets()
sheet_id = self.config.get("google_sp","sheet_id")
requests = []
requests.append({
"deleteDimension": {
"range": {
"sheetId": sheet_id,
"dimension": "ROWS",
"startIndex": sp_row,
"endIndex": sp_row + 1
}
}
})
body = {
"requests" : requests
}
sheet = service.spreadsheets()
res = sheet.batchUpdate(spreadsheetId=SAMPLE_SPREADSHEET_ID,body=body).execute()戻り値
成功すると変更されたシートと行数が返ってくる。
{
"spreadsheetId": string,
"replies": [
{
object (Response)
}
],
"updatedSpreadsheet": {
object (Spreadsheet)
}
}まとめ
今回は使用したAPIだけ記載しました。
今後使用するものも増えるかと思うのでその際は追記いていく所存です。
単純作業にお悩みではありませんか?
何百とあるワードを検索してファイルにまとめたり 数ある商品情報から条件にあるものだけ目で探してリ...
その単純作業プログラムで解決できるかもしれません。 もしよろしければ単純作業からの解放をお手伝いさせてください。
詳しくは以下のページからDM、または見積もり相談お願い致します。