

1. selenium使用の準備
Seleniumのインストール、使用するための準備が終わってない方は以下の記事を
参考にしてもらえれば助かります。
seleniumの準備
1.1. Webスクレイピングの注意点
わかりやすくまとまってる記事がありましたのでこちらをご参照
Qiita:Webスクレイピングの注意事項一覧
2. Googleで検索をしてみる
今回は以下のことをSeleniumを使って自動化する
- Seleniumを使ってGoogleの検索ページを開く
- 「Selenium」で検索する
- 表示されたサイト名を1ページ分取得する
2.1. 実装
ソースコードは以下のような感じ
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import configparser
from time import sleep
if __name__ == "__main__":
# cinfig使ってますが、別途記事にする。
# ChromeDriverのパスを取得しているだけ
config = configparser.ConfigParser()
config.read('appSetting.ini',encoding="utf-8")
webdriver_path = config.get("web_driver","chrome_driver")
# Googleの検索ページに遷移
browser = webdriver.Chrome(executable_path=webdriver_path)
browser.get("https://www.google.com/")
# ページ読み込みまで待機 かつ1秒待機
# 15秒待機でタイムアウト
WebDriverWait(browser, 15).until(EC.presence_of_all_elements_located)
sleep(2))
# 検索窓に「Selenium」を入力
browser.find_element_by_xpath("//input[@class=\"gLFyf gsfi\"]").send_keys("Selenium")
# 検索ボタン押下
browser.find_elements_by_class_name("gNO89b")[1].submit()
# ページ読み込みまで待機 かつ1秒待機
# 15秒待機でタイムアウト
WebDriverWait(browser, 15).until(EC.presence_of_all_elements_located)
sleep(2)
# 検索結果の要素群
res_list = browser.find_element_by_class_name("srg").find_elements_by_class_name("g")
# ループで回して各タイトルを出力
for res in res_list:
title = res.find_element_by_class_name("LC20lb").text
print(title)
実行結果
【超便利】PythonとSeleniumでブラウザを自動操作する方法まとめ ...
WebのUIテスト自動化 - Seleniumを使ってみる - Qiita
入門、Selenium - Seleniumの仕組み | CodeGrid
Webブラウザ自動化ツール「Selenium IDE」の今までとこれから ...
オープンソースの自動テストツール / Seleniumとは - OSSNews
非エンジニアのWebディレクターだけどSeleniumを触ってみた ...
PythonとSeleniumを使ったブラウザ自動操作 – 名古屋のWeb ...
Selenium何とかっていうツールがやたら色々あるのはどういうわけ ...
Selenium について — Selenium 日本語ドキュメント
[ThinkIT] 第1回:Webブラウザを使ったテストツールSeleniumとは ...
2.2 解説
2.2.1 指定のURLへ遷移
# Googleの検索ページに遷移
browser = webdriver.Chrome(executable_path=webdriver_path)
browser.get("https://www.google.com/")browser.get("ページのURL")で
指定したURLに遷移することができる。
2.2.2 待機
# ページ読み込みまで待機 かつ1秒待機
# 15秒待機でタイムアウト
WebDriverWait(browser, 15).until(EC.presence_of_all_elements_located)
sleep(2)WebDriverWait(browser, 15).until(EC.presence_of_all_elements_located)
でページが読み込み完了するまで待機する。
これをしないと、javascriptで表示される要素が取れなかったりエラーの原因となる。
sleep(2)はマナー的な所で、連続でサーバーにRequestを投げて負荷をかけないようするするため
2.2.3 要素を指定して任意の文字列を入力
# 検索窓に「Selenium」を入力
browser.find_element_by_xpath("//input[@class=\"gLFyf gsfi\"]").send_keys("Selenium")find_elementby○○でHTMLの要素を指定することができる。
その要素に対して「.send_keys("Selenium)」を使って「Slenium」という文字列を入力する
要素を指定するメソッドは他にも以下がある。
- find_element(s)_by_xpath
- find_element(s)_by_class_name
- find_element(s)_by_id
- find_element(s)_by_tag_name
- find_element(s)_by_css_selector
- find_element(s)_by_link_text
- find_element(s)_by_partial_link_text
elementのsがあるかないかで戻り値が変わる。
elementsはLilst、elementは単数(HTMLに複数あるのにelementを指定した場合は最初の要素)となる。
中でも個人的によく使うのは上3つ...
tag_nameはちょいちょい使うくらいの印象
実際にブラウザでF12を押下し、開発者ツールで見ると下記図のようになっている。
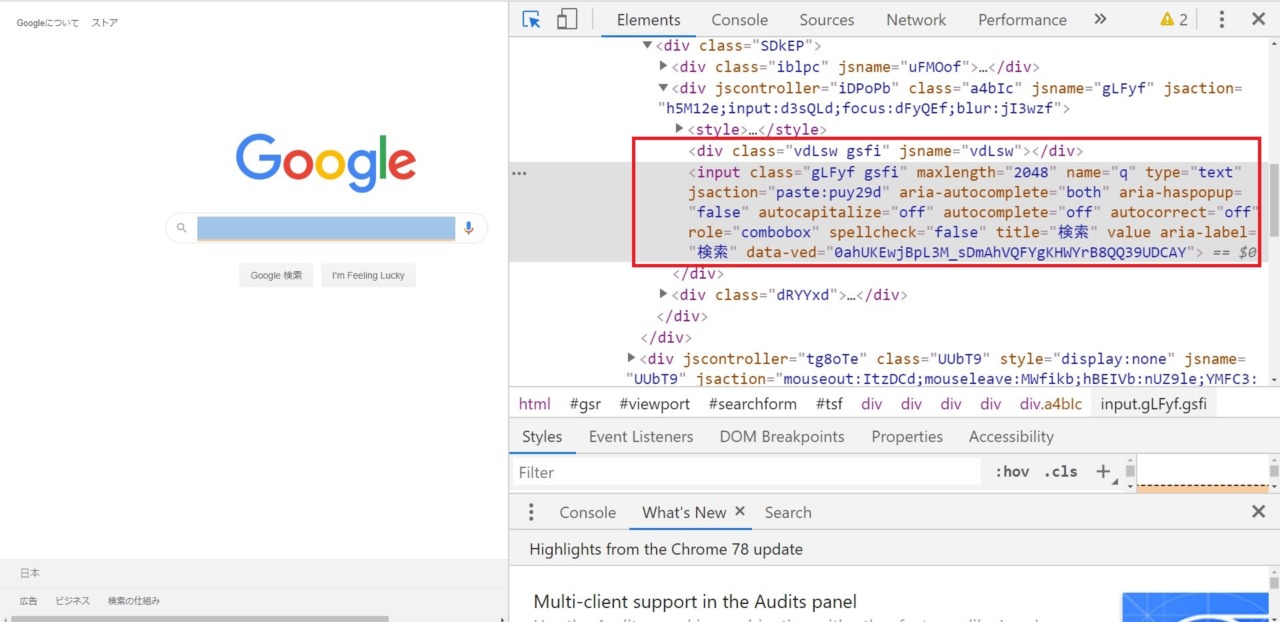
上の例ではxpathで指定しているが、classでも指定できる
# 検索窓に「Selenium」を入力
browser.find_element_by_class_name("gLFyf").send_keys("Selenium")開発者ツールではclass="gLFyf gsfi"になっているがこれは単純にclassが2つある認識でOK
なので
# 検索窓に「Selenium」を入力
browser.find_element_by_class_name("gsfi").send_keys("Selenium")でも結果は同じはず...
2.2.4 検索ボタン押下
# 検索ボタン押下
browser.find_elements_by_class_name("gNO89b")[1].submit()検索窓に入力が終わったら検索ボタンを押下する。
開発者ツールで見ると要素は「gNO89b」となっている。「gNO89b」は2つあるため
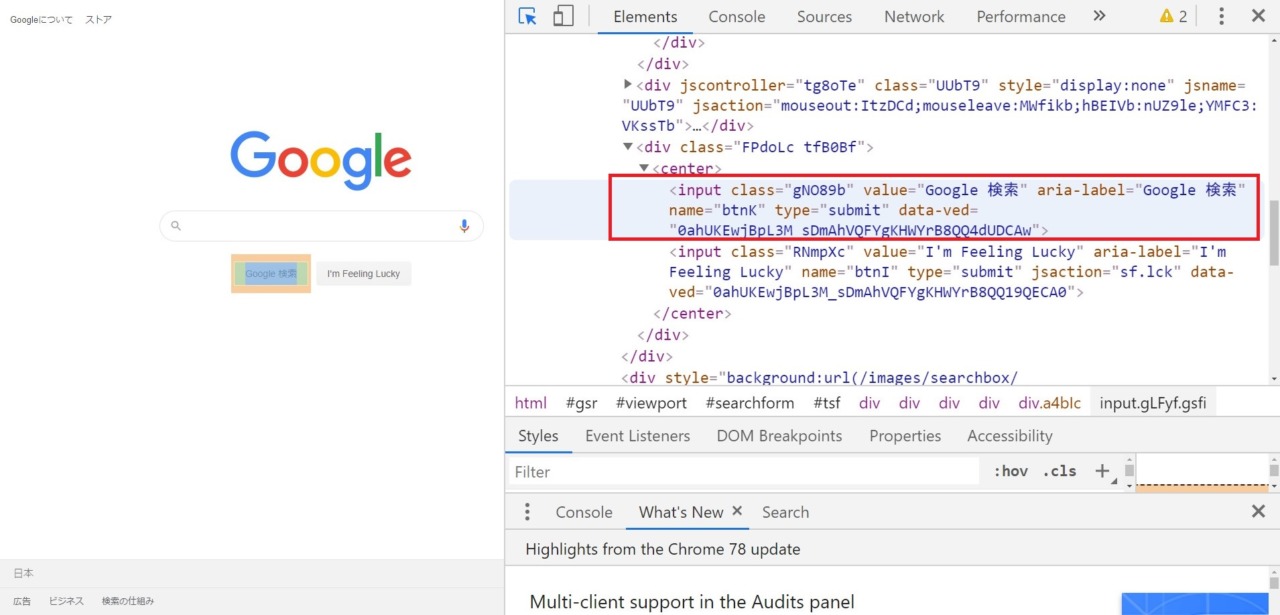
「find_elements_by_class_name」で取得し、2つ目を指定している。
その指定した要素をsubmit()している。
タグに「Button」タグがあれば.click()でもできたはず。
それは別の機会に。
2.2.5. 検索結果からタイトルを取得
# 検索結果の要素群
res_list = browser.find_element_by_class_name("srg").find_elements_by_class_name("g")
# ループで回して各タイトルを出力
for res in res_list:
title = res.find_element_by_class_name("LC20lb").text
print(title)検索結果のページ。
こういうページやAmazonとかショップのページはアイテムごとに要素が切られている。
ここでは検索結果全体の要素を取得し、その後に各ページごとの要素を指定している。
(自分の語彙力のなさに絶望しているので次の画像を見てもらうとわかりやすいかも)
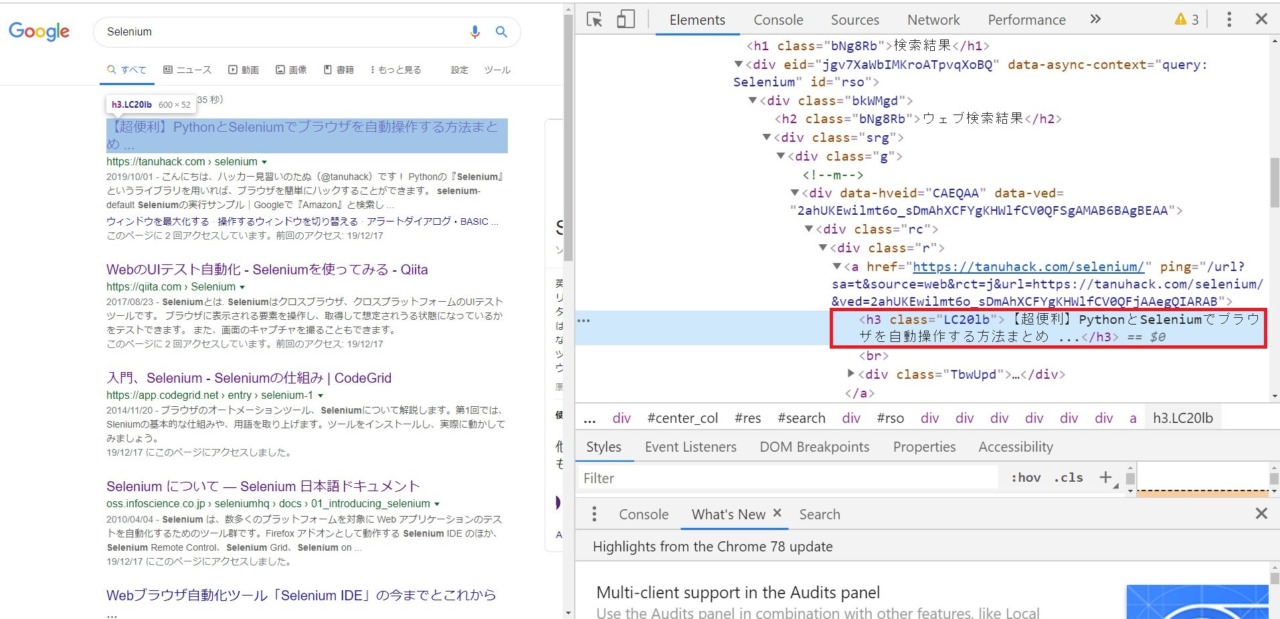
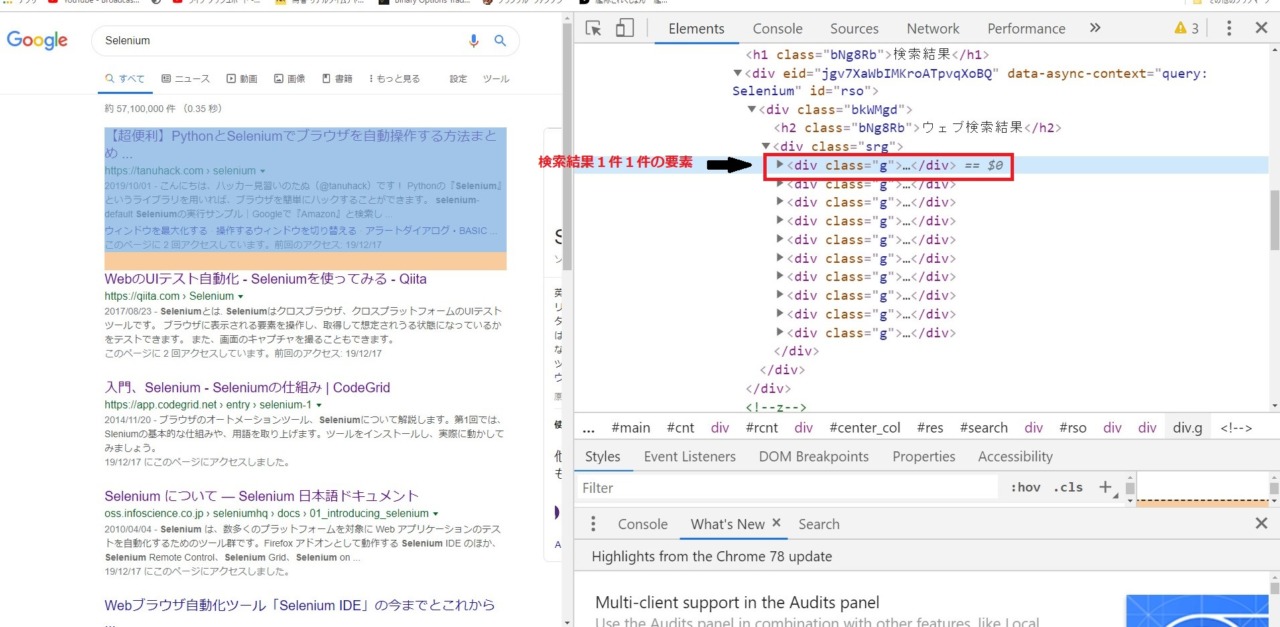
開発者ツールで見ると「srg」の名前の付いたclassがあり、その子要素に「g」という名前の付いた
1件ずつの検索結果のページが配置されている。
そのため、ソースコードでは「srg」を指定し、更に「g」の要素をfind_elements_class_nameで
全て指定している。
最後に、「g」の要素をループで回し、その下にある「LC20lb」のtextを指定している。
これでタイトルが取得できる。
単純作業にお悩みではありませんか?
何百とあるワードを検索してファイルにまとめたり 数ある商品情報から条件にあるものだけ目で探してリ...
その単純作業プログラムで解決できるかもしれません。 もしよろしければ単純作業からの解放をお手伝いさせてください。
詳しくは以下のページからDM、または見積もり相談お願い致します。